Caching
Contents 🔗︎
- What is a Cache
- How does the Cache Work?
- Cache Access Times
- Data and Instruction Caches
- Simulating the Cache
- A Practical Example
- Resources
What is a cache, and why do we have them?
What is a Cache 🔗︎
Caching is a mechanism designed - What is a Cache
By introducing a cache, we are able to increase our program’s performance.
Instead of always going to the main memory to fetch our data, we may be able to grab it from the L1 cache instead, which is a much faster operation.
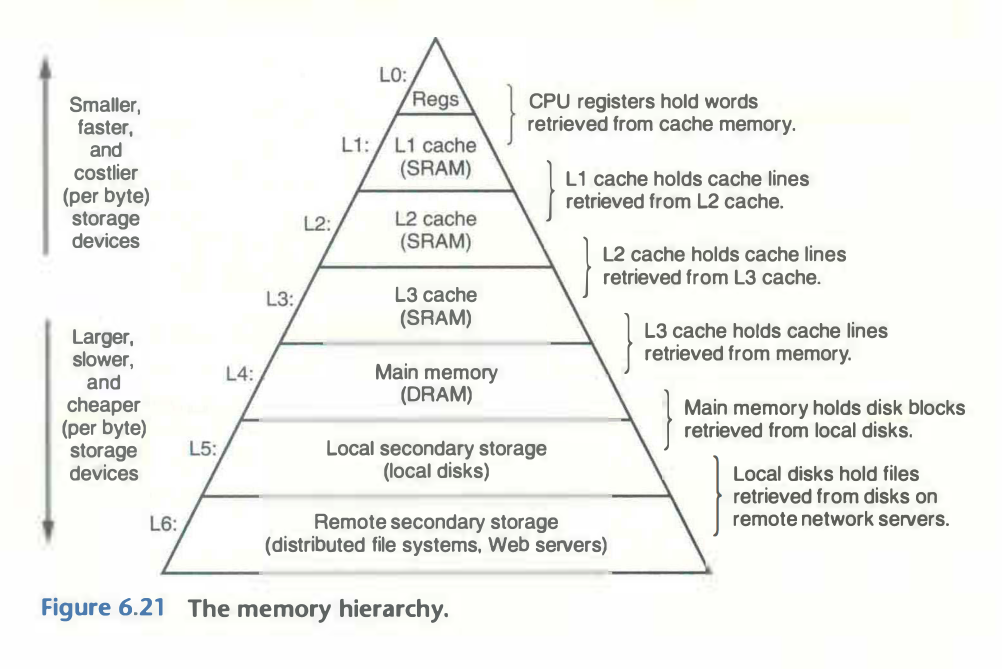
Spatial and Time Locality 🔗︎
The principle of locality
Programs tend to reuse data and instructions they have used recently1
Spatial locality is the idea that items who’s addresses are near each other will be accessed close in time.
Time locality is that those objects accessed recently will be more likely to be accessed again in the near future.
These principles guide us when creating and using caches.
Amdahl’s Law 🔗︎
Amdahl’s law states that the performance improvement to be gained from using some faster mode of execution is limited by the fraction of the time the faster mode can be used.1
If I can speed up part of my program by 100%, but it only makes up 10% of my total running time, then I have only saved 5% of the total running time of my program.
If I increase parts of my program performance, the gain is limited to the portion of time my program spends running that code.
In fact, in the above example, eliminating any time in the small program would still only reduce the total running time by 10%.
SRAM and DRAM 🔗︎
Static RAM (SRAM) is faster and more expensive and is used for cache memories. Dynamic RAM (DRAM) is slower and less expensive and is used for the main memory and graphics frame buffers2.
How does the Cache Work? 🔗︎
When a program needs data from cache level k+1, it looks for the data in cache level k.2
If we find the data in that cache, it’s called a cache hit, otherwise, it’s a called a cache miss.
When a cache miss occurs, the data must be fetched from a lower level and written into the cache.
Cache Hits 🔗︎
How do we know if we found the data in the cache?
The cache doesn’t just contain the data. It also contains a Tag and a Valid bit3.
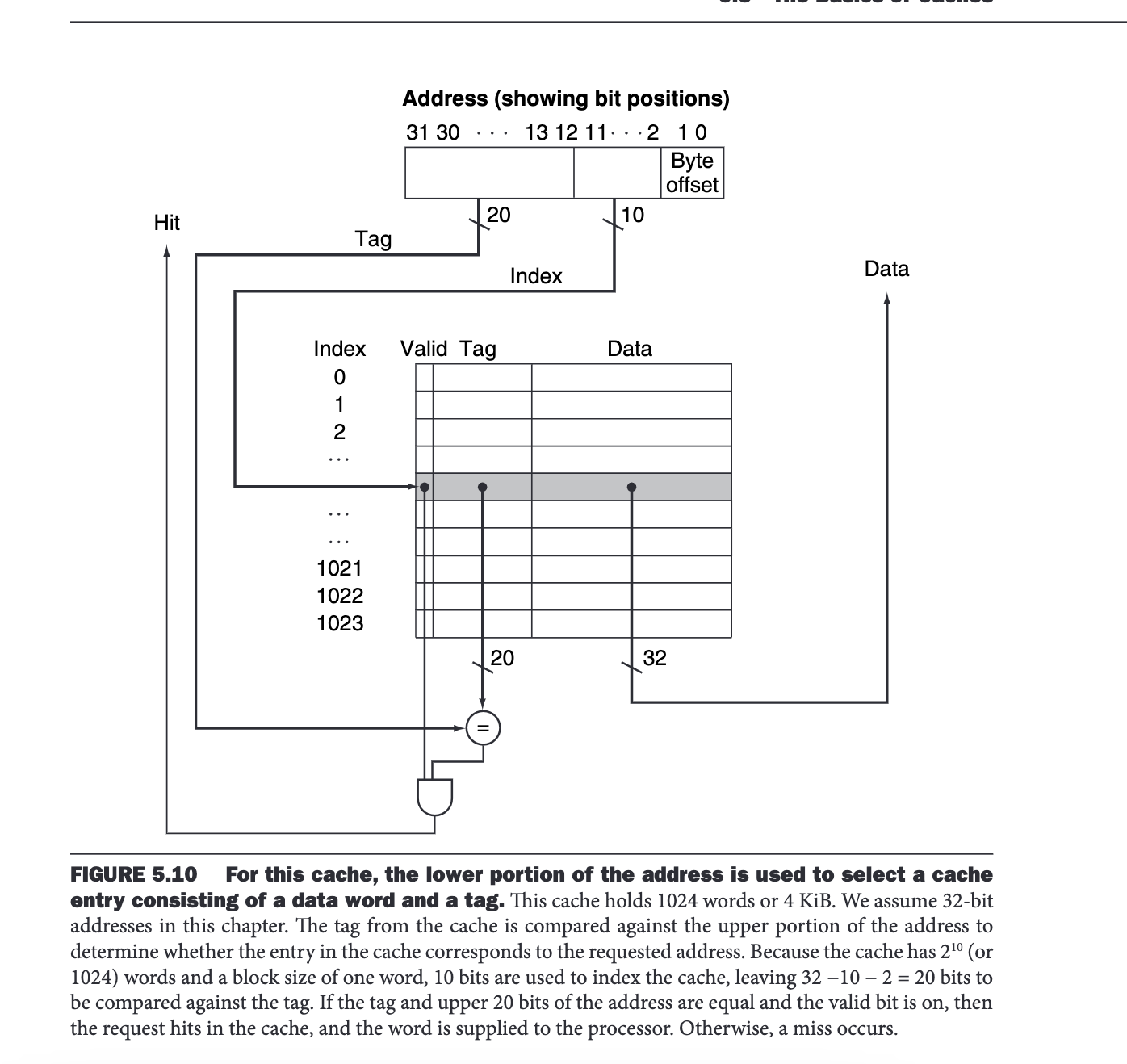
The Tag block contains information about what is contained in the cache block. We can search the cache for the relevant information, and if it is not there, we
Cache Misses: Writing to the Cache 🔗︎
When we have a cache miss we must do two things
- Fetch the data
- place the data in the cache
When we place new data in the cache, more data is moved than is required. Due to spatial locality, we assume that nearby data will also be needed in the near future. The size of the data moved is known as a cache line or a block. This may overwrite an existing line in the cache.
The transfer between cache levels is fixed between adjacent cache levels, and this gets larger the further we are from the CPU2. It makes sense to transfer more blocks into the cache the further down we are, to make up for the time taken to access this memory.
Caching Reads and Writes 🔗︎
Caching a READ operation is fairly intuitive. The state of the memory and the state of the cache will be the same.
What about caching WRITE operations? If we write to the cache, how is the memory updated?
There are two main strategies for managing WRITE operations in the cache, write-through and write-back 1.
A write-through cache writes both to the cache and to main memory. The addition of writing to main memory is known as writing through the cache.
A write-back cache only writes to the cache. When the cache memory is next overwritten, the cache will be copied back to main memory.
Both caching strategies use a write buffer, to allow processing to continue, even if the write to main memory has not been completed1.
How Does Data Move Between Caches 🔗︎
One of the questions I had was how data moves between caches. I know that when I write to some data not in the cache, I will write the new cache line to the L1 cache. I wanted to know how data ends up in the L2/L3 etc cache levels.
There are two kinds of caches, inclusive and exclusive caching .
Inclusive caching means that L1 contains everything in L2, which contains everything in L3 etc.
Exclusive means that data is only kept in the cache in one position.
For an inclusive cache, if data is found in L3, it will be written to L2, and then to L1. The writes to the smaller, higher level caches, will cause state data to be evicted.
Cache Access Times 🔗︎
A popular visualisation of cache fetch times is here .
Per this diagram, an L1 cache hit will take about 1ns to return, while a main memory reference will take 100ns.
Our program can run much faster by using the cache well!
Data and Instruction Caches 🔗︎
There are separate caches for Data and Instructions (Stack Overflow ). Read this Intel post for some interersting specs.
Another stack exchange post on this topic.
The Data cache holds the data to be read or executed.
The instruction cache holds instructions to execute.
The data cache changes much more frequently than the instruction cache.
Simulating the Cache 🔗︎
So how can I actually tell my usage of the cache when running my program?
We can use the valgrind
option cachegrind for this. It can simulate cache usage, so we can get an idea of how well our program is utilising the cache.
For example, compile your c binary with some thing like clang hell_world.c and then use valgrind to simulate the cache.
valgrind --tool=cachegrind --cache-sim=yes ./a.out
Then, view this with cg_annotate
You’ll be able to see a cache simulation, and see how well your cache levels are being utilised.
A Practical Example 🔗︎
Python List Implementation :
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
So a Python List is implemented as a list of pointers to PyObjects. This means, that when we iterate through a python list, we need to get the pointer to the object, and then get the object. Since the PyObject we want could be anywhere in memory and not necessarirly sequential, we will have a low probability of cache hits.
Instead, to have a more cache friendly Python List, we should use the array type . The Array type is better for our cache, since the elements in the array will be located in contiguous blocks in memory. When we fetch the first element, many of the subsequent elements will be loaded into the cache, which will increase our performance.
Read more about the Python List implementation here .
Resources 🔗︎
https://fgiesen.wordpress.com/2016/08/07/why-do-cpus-have-multiple-cache-levels/