My First Data Science Internship
Navigation 🔗︎
At the start of this year, I began my first internship as a Data Scientist. I was offered this role by the RAA, one of South Australia’s largest companies.
The RAA does many things, the main thing it is known for in South Australia is it’s road service program, where the RAA vans will come out to help you if you and your car run into a tricky situation. The RAA also offers a number of home insurance options, and now they are branching into travel planning and agency services.
The newly reformed travel section of the RAA was where much of my focus was during my weeks in the business.

The Interns (I’m on the right)
What Did I Learn? 🔗︎
My supervisor asked me on my final day, how I would summarise my internship, and I honestly struggled to find an answer. I learnt a LOT, and most of this wasn’t to do with data.
Meetings 🔗︎
As part of any business, people attend lots of meetings. My experience was no different. I attended and organised many meetings, and there were many aspects to this process that I will take into meetings in the future.
Meetings can easily turn into a big waste of time, so setting a clear direction for the meeting beforehand is very important. Tracking the meeting using minutes, and setting actions for people during and after the meeting is also a great way to hold people accountable, and to ensure the project gets finished on time.
This process can be easily applied to my university meetings, to make them more efficient. One really important part for me, is that people who are more prone to not getting stuff done, can be held accountable.
This meeting process doesn’t have to happen only during meetings with other people either. I feel that this process of setting an intention and accountability can be easily transferred to our own lives. Setting an intention for what you want to do and when you want to do it by, with some form of accountability, is exactly how good habits and progress are made.
Focussed Work 🔗︎
After reading books like Deep Work and Hyperfocus , I have a real strong connected with highly-focussed work. I try my best to integrate this style of work into my university study as I feel that I can get so much more done when I am in the zone.
One thing that I noticed while working is that this level of concentration seems to be very rarely achieved by people. This may have been RAA specific due to their open place and hot-desking situation, but I feel that other companies would also run into this problem. Constant meetings and coffee runs have such a big impact on how much work someone can do in a certain time frame, and this absolutely has an impact on overall productivity.
I understand it can be difficult to fit these times for deep work into a work day, but I also feel like businesses are missing out on a huge productivity boost by not making this more of a focus. For example, the way I structure my uni day is to arrive at 8am, to do focussed work until around 12-1, and then relax, watch lectures and begin to wind down. Businesses could easily take a similar approach by setting loose rules like ’no meetings before 12pm’ or similar. This allows people to really get the most out of their day by having set times for focussed productivity.
There may be some limitations to this approach as it’s really only knowledge workers that gain from this. The HR department for example doesn’t have nearly as much use for deep work time as the Data and Analytics area for example.

me practicing for our group presentation on Reward and Recognition software
Data Quality 🔗︎
Another problem that I hadn’t really been exposed to before this internship was that of Data Quality. If someone like me wants to complete some analysis on some data, it is super important that the data is correct, and there is as much of it as possible.
The travel data that we were using had a number of errors throughout, these errors meant less data could be used, and the data that was being used may still have some mistakes. These were mainly due to consultants inputting the data, having free text fields to put their information in.
Free text is a Big No No!
Free text makes it a nightmare to match data, as people often have different styles of inputting. Data Quality issues generally stem from the input source, so maximising the quality of the data really starts from the collection process.
Data Process 🔗︎
The full data process is something that I had heard about but didn’t really have a full grasp of. The data process involves the full process of collection, storing and using the data.
One big area is that of data engineering. Collecting data and placing it in a database in such a way that it is easy to access for people like me is a very important part of a business. SQL in particular is something that I hadn’t really been exposed to at all before, and now I realise how much of a vital role it plays in business, particularly in one of the size of the RAA. This is definitely an area I would love to learn more about.
My Work 🔗︎
So now we’ve gone through all the things that I’ve learnt, it’s time to get into what I actually did.
I was tasked with creating a model to predict a members next travel destination. I did this using software called ‘Knime’. It makes the entire data science process very easy to understand for those with no programming background. It’s really popular at the RAA, so that’s what I created my model in.
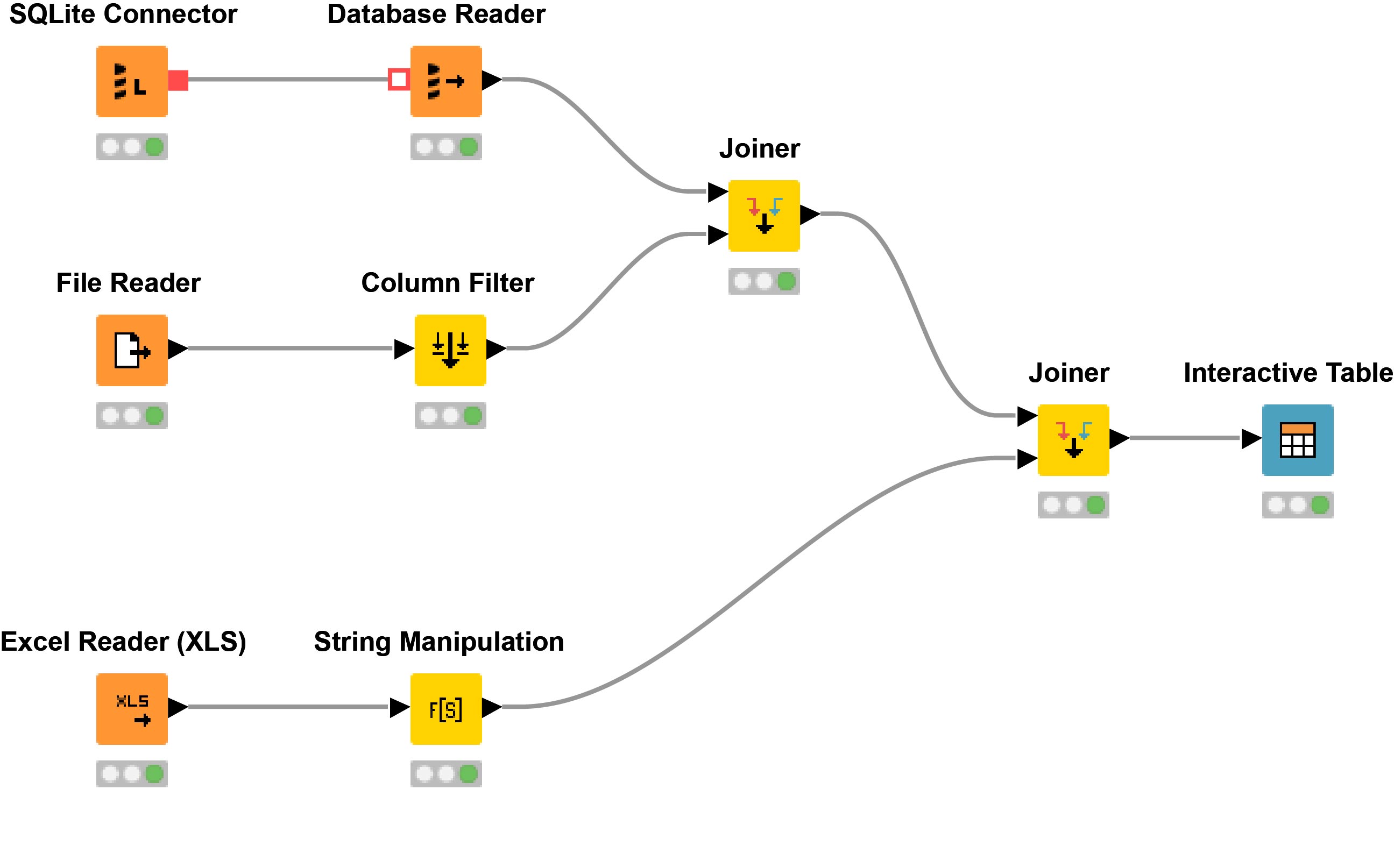
a Knime example
I was going to use machine learning to create my prediction, so I needed to find all the variables I thought would have some correlations to someones travel destination, and use those in my model.
I’m not sure how much detail I can go into so I won’t give out what data and columns I used. In the end though, I created a model to predict a members next travel destination with 70% accuracy. Not too bad.
Some limitations I had were that there weren’t many people in the database, and that each person only had a limited number of trips. These together made it hard to predict exact destinations, so I ended up predicting their travel region instead.
I used a Gradient Boosting model, which was really cool. This led me down the path of learning about XGBoost, and how gradient boosting algorithms actually work.
Summary 🔗︎
Overall, I learnt heaps about businesses, how they operate, and the role that data plays. I learnt heaps about what roles a data scientist can do, and this has me really excited for the future.
Thanks for reading! If you’d like to contact me please hit me up on Linkedin , or email me at [email protected]